
housing 데이터셋을 활용하여 데이터 전처리를 진행해보자!
- housing 데이터셋 다운로드 후 csv 형식의 파일을 pandas로 확인하는 것으로 시작.
- 훈련 세트와 테스트 세트를 구분하여 만들고, 고유 식별자를 이용하여 무작위로 테스트 세트를 만드는 것을 방지한다.
기본 설정
필수 모듈을 불러오고 그래프 출력 관련 기본 설정을 정한다.
# 파이썬 ≥3.5
import sys
assert sys.version_info >= (3, 5)
# 사이킷런 ≥0.20
import sklearn
assert sklearn.__version__ >= "0.20"
# 공통 모듈 임포트
import numpy as np
import os
# 깔금한 그래프 출력을 위해
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rc('axes', labelsize=14)
mpl.rc('xtick', labelsize=12)
mpl.rc('ytick', labelsize=12)
# 그림 저장 위치 지정
PROJECT_ROOT_DIR = "."
CHAPTER_ID = "end_to_end_project"
IMAGES_PATH = os.path.join(PROJECT_ROOT_DIR, "images", CHAPTER_ID)
os.makedirs(IMAGES_PATH, exist_ok=True)
def save_fig(fig_id, tight_layout=True, fig_extension="png", resolution=300):
path = os.path.join(IMAGES_PATH, fig_id + "." + fig_extension)
print("그림 저장:", fig_id)
if tight_layout:
plt.tight_layout()
plt.savefig(path, format=fig_extension, dpi=resolution)
0. 데이터 가져오기
0.1 데이터 다운로드
- 온라인 상에 저장된 압축파일을 가져오기
- 압축파일을 풀어 csv 파일로 저장
import os
import tarfile
import urllib.request
DOWNLOAD_ROOT = "https://raw.githubusercontent.com/codingalzi/handson-ml/master/"
HOUSING_PATH = os.path.join("datasets", "housing")
HOUSING_URL = DOWNLOAD_ROOT + "notebooks/datasets/housing/housing.tgz"
def fetch_housing_data(housing_url=HOUSING_URL, housing_path=HOUSING_PATH):
if not os.path.isdir(housing_path):
os.makedirs(housing_path)
tgz_path = os.path.join(housing_path, "housing.tgz")
urllib.request.urlretrieve(housing_url, tgz_path)
housing_tgz = tarfile.open(tgz_path)
housing_tgz.extractall(path=housing_path)
housing_tgz.close()
fetch_housing_data()
0.2 데이터 구조 훑어보기
- csv 파일을 판다스(ps: pandas) 데이터프레임으로 불러오기
import pandas as pd
def load_housing_data(housing_path=HOUSING_PATH):
csv_path = os.path.join(housing_path, "housing.csv")
return pd.read_csv(csv_path)
housing = load_housing_data()
housing.head()
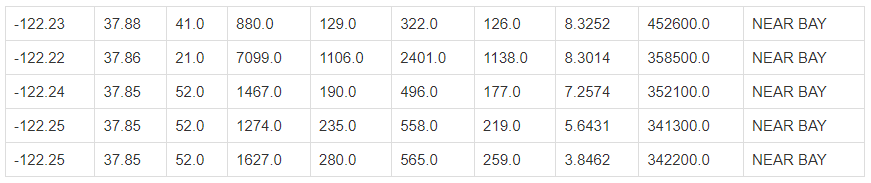
- 데이터셋 기본 정보 확인하기
housing.info()
RangeIndex: 20640 entries, 0 to 20639
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 longitude 20640 non-null float64
1 latitude 20640 non-null float64
2 housing_median_age 20640 non-null float64
3 total_rooms 20640 non-null float64
4 total_bedrooms 20433 non-null float64
5 population 20640 non-null float64
6 households 20640 non-null float64
7 median_income 20640 non-null float64
8 median_house_value 20640 non-null float64
9 ocean_proximity 20640 non-null object
dtypes: float64(9), object(1)
memory usage: 1.6+ MB
- 범주형 데이터 탐색
housing["ocean_proximity"].value_counts()
<1H OCEAN 9136
INLAND 6551
NEAR OCEAN 2658
NEAR BAY 2290
ISLAND 5
Name: ocean_proximity, dtype: int64
- 수치형 데이터 탐색
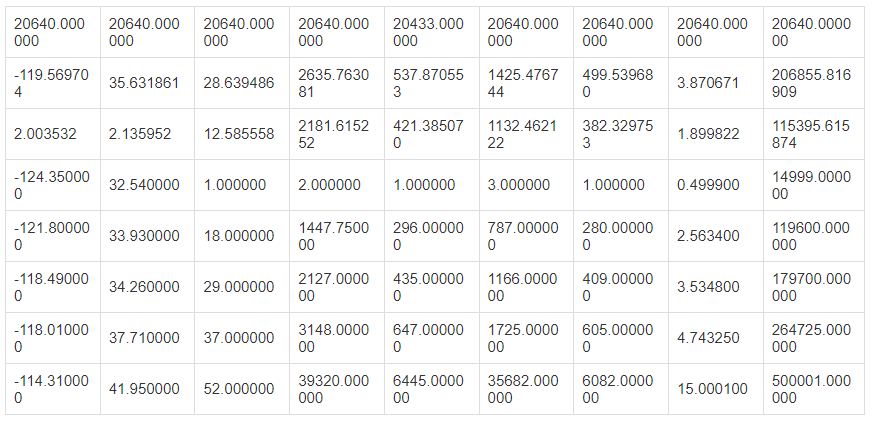
housing.describe()
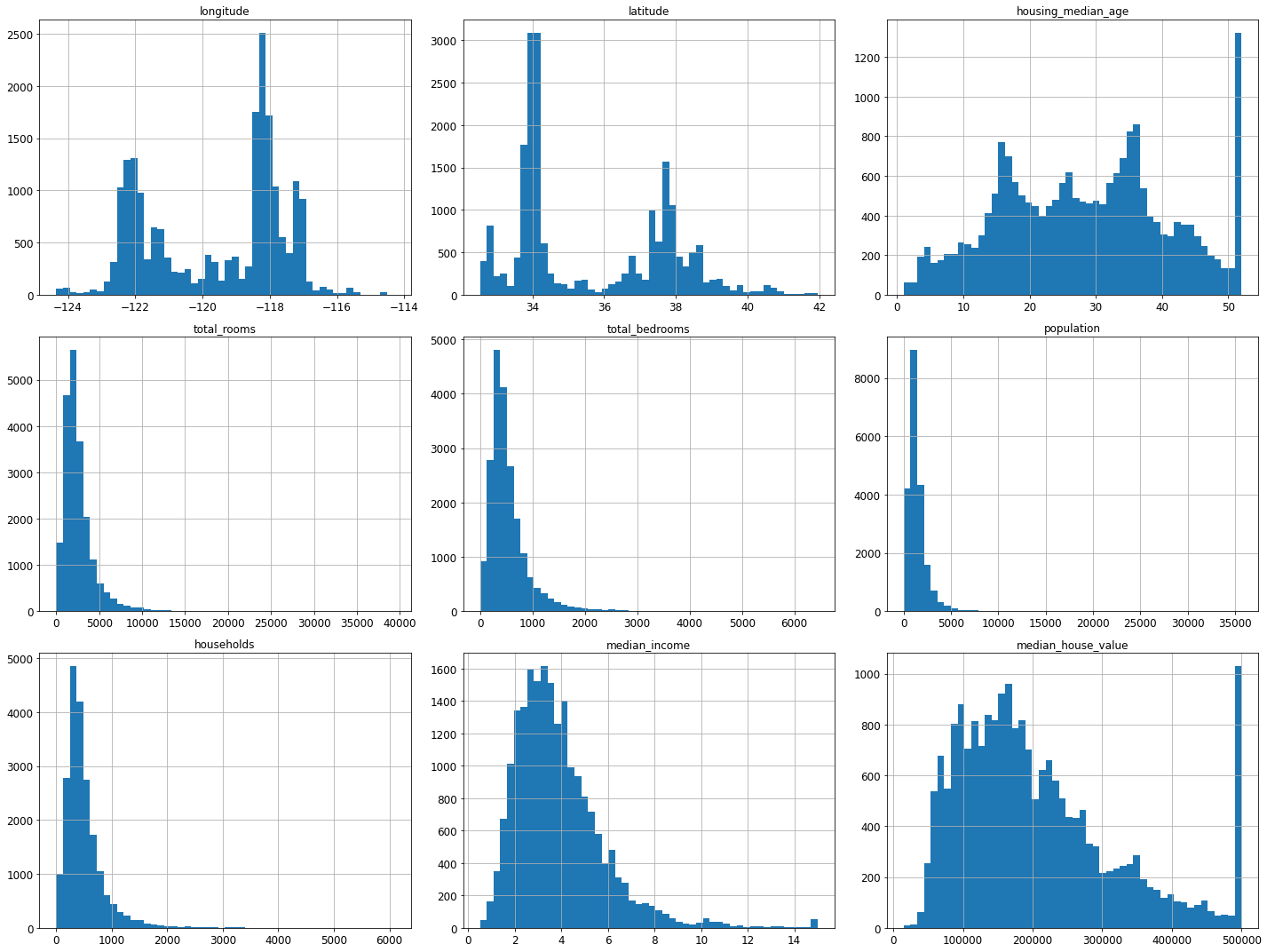
- 수치형 데이터 특성별 히스토그램
%matplotlib inline
import matplotlib.pyplot as plt
housing.hist(bins=50, figsize=(20,15))
save_fig("attribute_histogram_plots")
plt.show()
그림 저장: attribute_histogram_plots
0.3 테스트 세트 만들기
# 노트북의 실행 결과가 동일하도록
np.random.seed(42)
0.4 무작위 샘플링
- 훈련 세트와 테스트 세트 구분 연습하기
import numpy as np
# 예시 용도로 만든 훈련 세트/테스트 세트 분류 함수. 실전용 아님.
def split_train_test(data, test_ratio):
shuffled_indices = np.random.permutation(len(data))
test_set_size = int(len(data) * test_ratio)
test_indices = shuffled_indices[:test_set_size]
train_indices = shuffled_indices[test_set_size:]
return data.iloc[train_indices], data.iloc[test_indices]
train_set, test_set = split_train_test(housing, 0.2)
len(train_set)
16512len(test_set)
4128- 테스트 세트의 비율은 20%
len(test_set) / len(housing)
0.2
데이터를 확인하면서 보이는 문제점 찾기
- 실행할 때마다 완전히 새로 구분함
- 따라서 반복 훈련을 진행 할 경우 테스트 세트가 모델에 노출됨.
해결 방법: 샘플 고유의 식별자를 활용하여 식별자를 기준으로 훈련세트와 테스트 세트 구분
- ⭐ split_train_test_by_id() 함수
- 식별자의 체크섬을 기준으로 체크섬 값이 일정 백분율 이하인 샘플을 테스트 세트에 저장
- 체크섬(checksum): 파일 전송 과정에서 발생할 수 있는 손실 여부를 판단하기 위해 사용되는 값으로 파일이 달라지면 체크섬 값이 달라짐.
- 참고: 위키백과: 체크섬
- zlib.crc32() 함수: 파일의 체크섬을 CRC 방식으로 계산한 32비트 정수 반환
- CRC(순환 중복 검사): 파일의 체크섬을 계산하는 방식
- 0xffffffff: 32비트 정수 중에서 가장 큰 정수, 즉 2**32 - 1.
- test_ratio * 2**32: 32비트 정수 중에서 test_ratio 비율에 해당하는 정수 예를 들어, test_ratio = 0.2 이며, 하위 20%에 해당하는 정수.
- &: 이진 논리곱(binary AND)이라는 비트 연산자.
- 이진법으로 표현된 두 숫자의 논리곱 연산자
- 동일한 위치의 수가 둘 모두 1일 때만 1로 계산됨.
- 여기서는 0xffffffff와의 비트 연산을 통해 2**32 보다 작은 값으로 제한하기 위해 사용됨. 하지만 zlib.crc32() 함수가 32비트 정수를 반환하기에 굳이 사용할 필요 없음.
- 참고: 위키독스: 비트 연산자
from zlib import crc32
def test_set_check(identifier, test_ratio):
return crc32(np.int64(identifier)) & 0xffffffff < test_ratio * 2**32
def split_train_test_by_id(data, test_ratio, id_column):
ids = data[id_column]
in_test_set = ids.apply(lambda id_: test_set_check(id_, test_ratio))
return data.loc[~in_test_set], data.loc[in_test_set]
- 고유 식별자 생성법 1: 인덱스 활용
housing_with_id = housing.reset_index() # `index` 열이 추가된 데이터프레임 반환
train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, "index")
- 고유 식별자 생성법 2: 경도와 위도 활용
housing_with_id["id"] = housing["longitude"] * 1000 + housing["latitude"]
train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, "id")
test_set.head()
| 59 | -122.29 | 37.82 | 2.0 | 158.0 | 43.0 | 94.0 | 57.0 | 2.5625 | 60000.0 | NEAR BAY | -122252.18 |
| 60 | -122.29 | 37.83 | 52.0 | 1121.0 | 211.0 | 554.0 | 187.0 | 3.3929 | 75700.0 | NEAR BAY | -122252.17 |
| 61 | -122.29 | 37.82 | 49.0 | 135.0 | 29.0 | 86.0 | 23.0 | 6.1183 | 75000.0 | NEAR BAY | -122252.18 |
| 62 | -122.29 | 37.81 | 50.0 | 760.0 | 190.0 | 377.0 | 122.0 | 0.9011 | 86100.0 | NEAR BAY | -122252.19 |
| 67 | -122.29 | 37.80 | 52.0 | 1027.0 | 244.0 | 492.0 | 147.0 | 2.6094 | 81300.0 | NEAR BAY | -122252.20 |
- 사이킷런의 무작위 구분 함수
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)
test_set.head()
| -119.01 | 36.06 | 25.0 | 1505.0 | NaN | 1392.0 | 359.0 | 1.6812 | 47700.0 | INLAND |
| -119.46 | 35.14 | 30.0 | 2943.0 | NaN | 1565.0 | 584.0 | 2.5313 | 45800.0 | INLAND |
| -122.44 | 37.80 | 52.0 | 3830.0 | NaN | 1310.0 | 963.0 | 3.4801 | 500001.0 | NEAR BAY |
| -118.72 | 34.28 | 17.0 | 3051.0 | NaN | 1705.0 | 495.0 | 5.7376 | 218600.0 | <1H OCEAN |
| -121.93 | 36.62 | 34.0 | 2351.0 | NaN | 1063.0 | 428.0 | 3.7250 | 278000.0 | NEAR OCEAN |
- 무작위 구분의 단점
- 계층별 특성을 고려하지 못함
0.5 계층적 샘플링
- 전체 데이터셋의 중간 소득 히스토그램
housing["median_income"].hist()
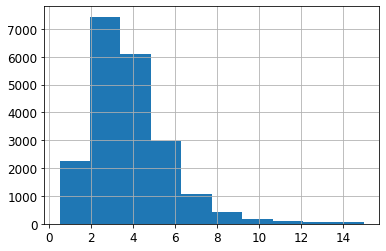
- 대부분 구역의 중간 소득이 1.5~6.0(15,000~60,000$) 사이
- 소득 구간을 아래 숫자를 기준으로 5개로 구분
-
[0, 1.5, 3.0, 4.6, 6.0, np,inf]
- 5개의 카테고리를 갖는 특성 추가
- 특성값: 1, 2, 3, 4, 5
housing["income_cat"] = pd.cut(housing["median_income"],
bins=[0., 1.5, 3.0, 4.5, 6., np.inf],
labels=[1, 2, 3, 4, 5])
- 계층(소득 구간) 특성 히스토그램
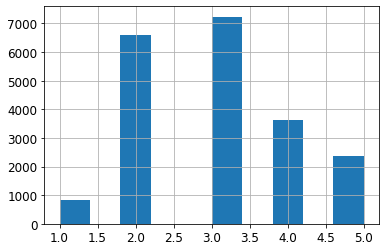
housing["income_cat"].value_counts()
3 7236
2 6581
4 3639
5 2362
1 822
Name: income_cat, dtype: int64housing["income_cat"].hist()
- 계층별 샘플링 실행
- housing["income_cat"] 기준
from sklearn.model_selection import StratifiedShuffleSplit
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for train_index, test_index in split.split(housing, housing["income_cat"]):
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[test_index]
- 소득 계층 비율이 유지되었음을 확인 가능
strat_test_set["income_cat"].value_counts() / len(strat_test_set)
3 0.350533
2 0.318798
4 0.176357
5 0.114583
1 0.039729
Name: income_cat, dtype: float64housing["income_cat"].value_counts() / len(housing)
3 0.350581
2 0.318847
4 0.176308
5 0.114438
1 0.039826
Name: income_cat, dtype: float64- 무작위 샘플링 대 계층별 샘플링 결과 비교
def income_cat_proportions(data):
return data["income_cat"].value_counts() / len(data)
train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)
compare_props = pd.DataFrame({
"Overall": income_cat_proportions(housing),
"Stratified": income_cat_proportions(strat_test_set),
"Random": income_cat_proportions(test_set),
}).sort_index()
compare_props["Rand. %error"] = 100 * compare_props["Random"] / compare_props["Overall"] - 100
compare_props["Strat. %error"] = 100 * compare_props["Stratified"] / compare_props["Overall"] - 100
compare_props
| 0.039826 | 0.039729 | 0.040213 | 0.973236 | -0.243309 |
| 0.318847 | 0.318798 | 0.324370 | 1.732260 | -0.015195 |
| 0.350581 | 0.350533 | 0.358527 | 2.266446 | -0.013820 |
| 0.176308 | 0.176357 | 0.167393 | -5.056334 | 0.027480 |
| 0.114438 | 0.114583 | 0.109496 | -4.318374 | 0.127011 |
- 데이터 되돌리기
- income_cat 특성 삭제
- 이제 본격적으로 학습 시작할 것임
for set_ in (strat_train_set, strat_test_set):
set_.drop("income_cat", axis=1, inplace=True)
여기까지 데이터 전처리 전 데이터 다운로드 및 데이터 구조를 훑어보았다.
추가로 머신러닝 진행을 위해 split_train_test_by_id() 함수를 통해서 20% 비율의 테스트 세트를 만들었고, 인덱스나 경도, 위도 활용해서 식별자를 생성하는 법을 배웠다(데이터 전처리 과정에서는 사용하지는 않았음).
그리고 수치형 데이터를 계층적[0., 1.5, 3.0, 4.5, 6., np, inf]으로 샘플링해서 무작위로 샘플링을 한 것과 비교해봤다.
이제 앞서 데이터를 가져온 곳부터 되돌리고 본격적으로 전처리 과정을 진행해보자.
housing 데이터셋을 활용하여 데이터 전처리를 진행해보자!
- housing 데이터셋 다운로드 후 csv 형식의 파일을 pandas로 확인하는 것으로 시작.
- 훈련 세트와 테스트 세트를 구분하여 만들고, 고유 식별자를 이용하여 무작위로 테스트 세트를 만드는 것을 방지한다.
기본 설정
필수 모듈을 불러오고 그래프 출력 관련 기본 설정을 정한다.
# 파이썬 ≥3.5
import sys
assert sys.version_info >= (3, 5)
# 사이킷런 ≥0.20
import sklearn
assert sklearn.__version__ >= "0.20"
# 공통 모듈 임포트
import numpy as np
import os
# 깔금한 그래프 출력을 위해
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rc('axes', labelsize=14)
mpl.rc('xtick', labelsize=12)
mpl.rc('ytick', labelsize=12)
# 그림 저장 위치 지정
PROJECT_ROOT_DIR = "."
CHAPTER_ID = "end_to_end_project"
IMAGES_PATH = os.path.join(PROJECT_ROOT_DIR, "images", CHAPTER_ID)
os.makedirs(IMAGES_PATH, exist_ok=True)
def save_fig(fig_id, tight_layout=True, fig_extension="png", resolution=300):
path = os.path.join(IMAGES_PATH, fig_id + "." + fig_extension)
print("그림 저장:", fig_id)
if tight_layout:
plt.tight_layout()
plt.savefig(path, format=fig_extension, dpi=resolution)
0. 데이터 가져오기
0.1 데이터 다운로드
- 온라인 상에 저장된 압축파일을 가져오기
- 압축파일을 풀어 csv 파일로 저장
import os
import tarfile
import urllib.request
DOWNLOAD_ROOT = "https://raw.githubusercontent.com/codingalzi/handson-ml/master/"
HOUSING_PATH = os.path.join("datasets", "housing")
HOUSING_URL = DOWNLOAD_ROOT + "notebooks/datasets/housing/housing.tgz"
def fetch_housing_data(housing_url=HOUSING_URL, housing_path=HOUSING_PATH):
if not os.path.isdir(housing_path):
os.makedirs(housing_path)
tgz_path = os.path.join(housing_path, "housing.tgz")
urllib.request.urlretrieve(housing_url, tgz_path)
housing_tgz = tarfile.open(tgz_path)
housing_tgz.extractall(path=housing_path)
housing_tgz.close()
fetch_housing_data()
0.2 데이터 구조 훑어보기
- csv 파일을 판다스(ps: pandas) 데이터프레임으로 불러오기
import pandas as pd
def load_housing_data(housing_path=HOUSING_PATH):
csv_path = os.path.join(housing_path, "housing.csv")
return pd.read_csv(csv_path)
housing = load_housing_data()
housing.head()
- 데이터셋 기본 정보 확인하기
housing.info()
RangeIndex: 20640 entries, 0 to 20639
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 longitude 20640 non-null float64
1 latitude 20640 non-null float64
2 housing_median_age 20640 non-null float64
3 total_rooms 20640 non-null float64
4 total_bedrooms 20433 non-null float64
5 population 20640 non-null float64
6 households 20640 non-null float64
7 median_income 20640 non-null float64
8 median_house_value 20640 non-null float64
9 ocean_proximity 20640 non-null object
dtypes: float64(9), object(1)
memory usage: 1.6+ MB
- 범주형 데이터 탐색
housing["ocean_proximity"].value_counts()
<1H OCEAN 9136
INLAND 6551
NEAR OCEAN 2658
NEAR BAY 2290
ISLAND 5
Name: ocean_proximity, dtype: int64
- 수치형 데이터 탐색
housing.describe()
- 수치형 데이터 특성별 히스토그램
%matplotlib inline
import matplotlib.pyplot as plt
housing.hist(bins=50, figsize=(20,15))
save_fig("attribute_histogram_plots")
plt.show()
그림 저장: attribute_histogram_plots
0.3 테스트 세트 만들기
# 노트북의 실행 결과가 동일하도록
np.random.seed(42)
0.4 무작위 샘플링
- 훈련 세트와 테스트 세트 구분 연습하기
import numpy as np
# 예시 용도로 만든 훈련 세트/테스트 세트 분류 함수. 실전용 아님.
def split_train_test(data, test_ratio):
shuffled_indices = np.random.permutation(len(data))
test_set_size = int(len(data) * test_ratio)
test_indices = shuffled_indices[:test_set_size]
train_indices = shuffled_indices[test_set_size:]
return data.iloc[train_indices], data.iloc[test_indices]
train_set, test_set = split_train_test(housing, 0.2)
len(train_set)
16512len(test_set)
4128- 테스트 세트의 비율은 20%
len(test_set) / len(housing)
0.2
데이터를 확인하면서 보이는 문제점 찾기
- 실행할 때마다 완전히 새로 구분함
- 따라서 반복 훈련을 진행 할 경우 테스트 세트가 모델에 노출됨.
해결 방법: 샘플 고유의 식별자를 활용하여 식별자를 기준으로 훈련세트와 테스트 세트 구분
- ⭐ split_train_test_by_id() 함수
- 식별자의 체크섬을 기준으로 체크섬 값이 일정 백분율 이하인 샘플을 테스트 세트에 저장
- 체크섬(checksum): 파일 전송 과정에서 발생할 수 있는 손실 여부를 판단하기 위해 사용되는 값으로 파일이 달라지면 체크섬 값이 달라짐.
- 참고: 위키백과: 체크섬
- zlib.crc32() 함수: 파일의 체크섬을 CRC 방식으로 계산한 32비트 정수 반환
- CRC(순환 중복 검사): 파일의 체크섬을 계산하는 방식
- 0xffffffff: 32비트 정수 중에서 가장 큰 정수, 즉 2**32 - 1.
- test_ratio * 2**32: 32비트 정수 중에서 test_ratio 비율에 해당하는 정수 예를 들어, test_ratio = 0.2 이며, 하위 20%에 해당하는 정수.
- &: 이진 논리곱(binary AND)이라는 비트 연산자.
- 이진법으로 표현된 두 숫자의 논리곱 연산자
- 동일한 위치의 수가 둘 모두 1일 때만 1로 계산됨.
- 여기서는 0xffffffff와의 비트 연산을 통해 2**32 보다 작은 값으로 제한하기 위해 사용됨. 하지만 zlib.crc32() 함수가 32비트 정수를 반환하기에 굳이 사용할 필요 없음.
- 참고: 위키독스: 비트 연산자
from zlib import crc32
def test_set_check(identifier, test_ratio):
return crc32(np.int64(identifier)) & 0xffffffff < test_ratio * 2**32
def split_train_test_by_id(data, test_ratio, id_column):
ids = data[id_column]
in_test_set = ids.apply(lambda id_: test_set_check(id_, test_ratio))
return data.loc[~in_test_set], data.loc[in_test_set]
- 고유 식별자 생성법 1: 인덱스 활용
housing_with_id = housing.reset_index() # `index` 열이 추가된 데이터프레임 반환
train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, "index")
- 고유 식별자 생성법 2: 경도와 위도 활용
housing_with_id["id"] = housing["longitude"] * 1000 + housing["latitude"]
train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, "id")
test_set.head()
| 59 | -122.29 | 37.82 | 2.0 | 158.0 | 43.0 | 94.0 | 57.0 | 2.5625 | 60000.0 | NEAR BAY | -122252.18 |
| 60 | -122.29 | 37.83 | 52.0 | 1121.0 | 211.0 | 554.0 | 187.0 | 3.3929 | 75700.0 | NEAR BAY | -122252.17 |
| 61 | -122.29 | 37.82 | 49.0 | 135.0 | 29.0 | 86.0 | 23.0 | 6.1183 | 75000.0 | NEAR BAY | -122252.18 |
| 62 | -122.29 | 37.81 | 50.0 | 760.0 | 190.0 | 377.0 | 122.0 | 0.9011 | 86100.0 | NEAR BAY | -122252.19 |
| 67 | -122.29 | 37.80 | 52.0 | 1027.0 | 244.0 | 492.0 | 147.0 | 2.6094 | 81300.0 | NEAR BAY | -122252.20 |
- 사이킷런의 무작위 구분 함수
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)
test_set.head()
| -119.01 | 36.06 | 25.0 | 1505.0 | NaN | 1392.0 | 359.0 | 1.6812 | 47700.0 | INLAND |
| -119.46 | 35.14 | 30.0 | 2943.0 | NaN | 1565.0 | 584.0 | 2.5313 | 45800.0 | INLAND |
| -122.44 | 37.80 | 52.0 | 3830.0 | NaN | 1310.0 | 963.0 | 3.4801 | 500001.0 | NEAR BAY |
| -118.72 | 34.28 | 17.0 | 3051.0 | NaN | 1705.0 | 495.0 | 5.7376 | 218600.0 | <1H OCEAN |
| -121.93 | 36.62 | 34.0 | 2351.0 | NaN | 1063.0 | 428.0 | 3.7250 | 278000.0 | NEAR OCEAN |
- 무작위 구분의 단점
- 계층별 특성을 고려하지 못함
0.5 계층적 샘플링
- 전체 데이터셋의 중간 소득 히스토그램
housing["median_income"].hist()
- 대부분 구역의 중간 소득이 1.5~6.0(15,000~60,000$) 사이
- 소득 구간을 아래 숫자를 기준으로 5개로 구분
-
[0, 1.5, 3.0, 4.6, 6.0, np,inf]
- 5개의 카테고리를 갖는 특성 추가
- 특성값: 1, 2, 3, 4, 5
housing["income_cat"] = pd.cut(housing["median_income"],
bins=[0., 1.5, 3.0, 4.5, 6., np.inf],
labels=[1, 2, 3, 4, 5])
- 계층(소득 구간) 특성 히스토그램
housing["income_cat"].value_counts()
3 7236
2 6581
4 3639
5 2362
1 822
Name: income_cat, dtype: int64housing["income_cat"].hist()
- 계층별 샘플링 실행
- housing["income_cat"] 기준
from sklearn.model_selection import StratifiedShuffleSplit
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for train_index, test_index in split.split(housing, housing["income_cat"]):
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[test_index]
- 소득 계층 비율이 유지되었음을 확인 가능
strat_test_set["income_cat"].value_counts() / len(strat_test_set)
3 0.350533
2 0.318798
4 0.176357
5 0.114583
1 0.039729
Name: income_cat, dtype: float64housing["income_cat"].value_counts() / len(housing)
3 0.350581
2 0.318847
4 0.176308
5 0.114438
1 0.039826
Name: income_cat, dtype: float64- 무작위 샘플링 대 계층별 샘플링 결과 비교
def income_cat_proportions(data):
return data["income_cat"].value_counts() / len(data)
train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)
compare_props = pd.DataFrame({
"Overall": income_cat_proportions(housing),
"Stratified": income_cat_proportions(strat_test_set),
"Random": income_cat_proportions(test_set),
}).sort_index()
compare_props["Rand. %error"] = 100 * compare_props["Random"] / compare_props["Overall"] - 100
compare_props["Strat. %error"] = 100 * compare_props["Stratified"] / compare_props["Overall"] - 100
compare_props
| 0.039826 | 0.039729 | 0.040213 | 0.973236 | -0.243309 |
| 0.318847 | 0.318798 | 0.324370 | 1.732260 | -0.015195 |
| 0.350581 | 0.350533 | 0.358527 | 2.266446 | -0.013820 |
| 0.176308 | 0.176357 | 0.167393 | -5.056334 | 0.027480 |
| 0.114438 | 0.114583 | 0.109496 | -4.318374 | 0.127011 |
- 데이터 되돌리기
- income_cat 특성 삭제
- 이제 본격적으로 학습 시작할 것임
for set_ in (strat_train_set, strat_test_set):
set_.drop("income_cat", axis=1, inplace=True)
여기까지 데이터 전처리 전 데이터 다운로드 및 데이터 구조를 훑어보았다.
추가로 머신러닝 진행을 위해 split_train_test_by_id() 함수를 통해서 20% 비율의 테스트 세트를 만들었고, 인덱스나 경도, 위도 활용해서 식별자를 생성하는 법을 배웠다(데이터 전처리 과정에서는 사용하지는 않았음).
그리고 수치형 데이터를 계층적[0., 1.5, 3.0, 4.5, 6., np, inf]으로 샘플링해서 무작위로 샘플링을 한 것과 비교해봤다.
이제 앞서 데이터를 가져온 곳부터 되돌리고 본격적으로 전처리 과정을 진행해보자.