
설명하기 앞서 랜덤 포레스트와 스태킹 모델에 대해서 설명하자면 다음을 이해하면 된다.
랜덤포레스트(Random Forest)란?
우리는 머신러닝으로 데이터 속 특성(Feature)을 수정하거나 결정하는 것을 알 수 있다. 이 특성 정보를 기반으로 데이터를 분리하는 과정을 의사 결정 트리(Decision Tree)라고 한다.
보통 나무(Tree)들이 모여있는 장소를 숲(Forest)이라고 하는데, 랜덤 포레스트(Random Forest)는 이런 의사 결정 트리(Decision Tree)가 모여있는 장소라고 생각하면 된다.
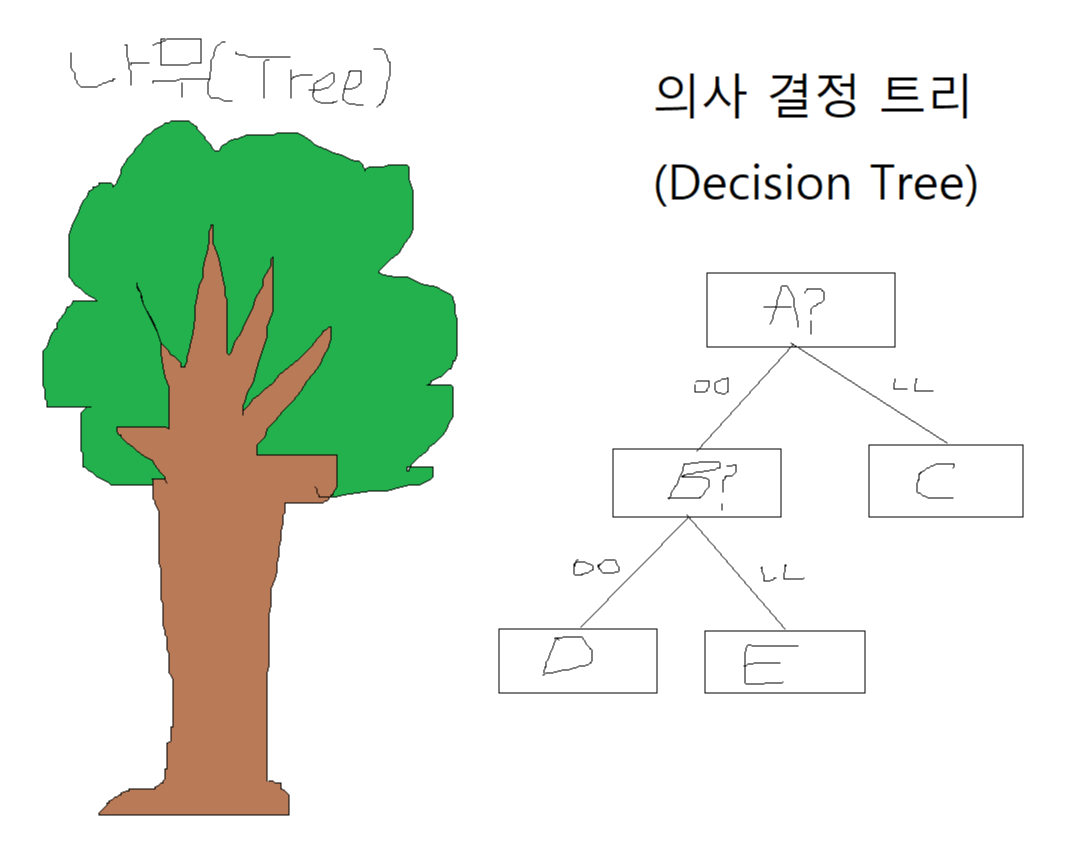
의사 결정 트리에서 한 두가지 요소로 결정하는 것 보다 여러가지 요소를 통해 결정할수록 더 자세한 예측을 할 수 있을 것이다. 그치만 수많은 요소(Feature)들을 가지고 하나의 결정 트리를 만든다고 한다면 가지가 너무 많아 오버피팅의 문제가 생길 수 있다.
즉 랜덤포레스트란 수많은 특성(Feature)들 중에 무작위(Random)로 일부만 선택하여 결정 트리를 생성하고, 이 과정을 여러 번 거쳐 여러 개의 의사 결정 트리를 만드는 방법이다.
여러 결정 트리들의 예측 값 중 가장 많이 나온 값을 최종 예측값으로 정하게 된다.
스태킹(Stacking)란?
스태킹은 여러가지 모델들의 예측값을 최종 모델의 학습 데이터로 사용하는 것이다. 아마 이름도 스택(Stack)이라는 쌓는다는 느낌의 자료구조 형식에서 유래한 것 같다.
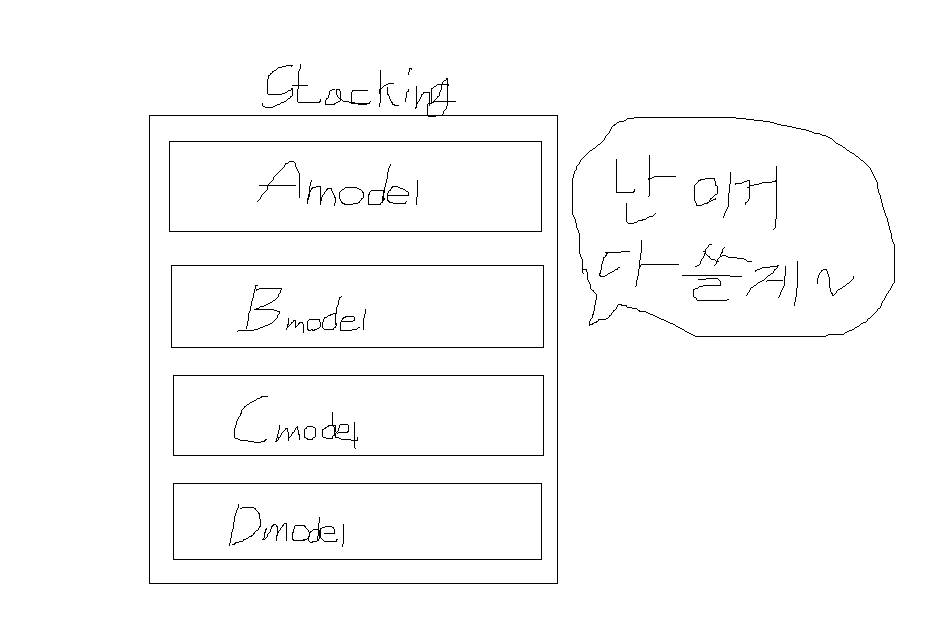
간단하게만 설명하자면 이 정도고, 자세한 거는 다른 사람 글 참고하는게 좋을 것 같다.
이제 구현하는 것을 진행해보자.
아 참고로 스태킹 모델 설명보면서 나머지 기본 모델들은 어떻게 구현하냐 생각할 수 있는데,
그거는 그냥 사이킷런으로 들고왔습니다. 머쓱ㅎㅎ;;
기본 설정
- 필수 모듈 불러오기
- 그래프 출력 관련 기본 설정 지정
# 파이썬 ≥3.5 필수 (파이썬 3.7 추천)
import sys
assert sys.version_info >= (3, 5)
# 사이킷런 ≥0.20 필수
import sklearn
assert sklearn.__version__ >= "0.20"
# 공통 모듈 임포트
import numpy as np
import os
# 노트북 실행 결과를 동일하게 유지하기 위해
np.random.seed(42)
# 깔끔한 그래프 출력을 위해
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rc('axes', labelsize=14)
mpl.rc('xtick', labelsize=12)
mpl.rc('ytick', labelsize=12)
# 그림을 저장할 위치
PROJECT_ROOT_DIR = "."
CHAPTER_ID = "decision_trees"
IMAGES_PATH = os.path.join(PROJECT_ROOT_DIR, "images", CHAPTER_ID)
os.makedirs(IMAGES_PATH, exist_ok=True)
def save_fig(fig_id, tight_layout=True, fig_extension="png", resolution=300):
path = os.path.join(IMAGES_PATH, fig_id + "." + fig_extension)
print("Saving figure", fig_id)
if tight_layout:
plt.tight_layout()
plt.savefig(path, format=fig_extension, dpi=resolution)
문제 1: 6장 연습문제 8번
랜덤 포레스트를 직접 구현한 다음에 7장에서 소개한 사이킷런의 랜덤 포레스트 모델을 사용하는 것과의 성능을 비교하라.
직접구현 랜덤 포레스트(accuracy_score: 0.872)
make_moons 데이터셋을 생성
- make_moons(n_samples=10000, noise=0.4) 이용
- 결과를 일정하게 만들기 위해 random_state=42 추가
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=10000, noise=0.4, random_state=42)
make_moons 데이터셋을 train 세트와 test 세트 분할
- train_test_split() 사용
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
DecisionTreeClassifier의 최적 하이퍼 파라미터 찾기: 교차 검증과 그리드 탐색 활용
- GridSearchCV 활용
- max_leaf_nodes 다양한 값 사용
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV
params = {'max_leaf_nodes': list(range(2, 100)), 'min_samples_split': [2, 3, 4]}
grid_search_cv = GridSearchCV(DecisionTreeClassifier(random_state=42), params, verbose=1, cv=3)
grid_search_cv.fit(X_train, y_train)
Fitting 3 folds for each of 294 candidates, totalling 882 fits
GridSearchCV(cv=3, error_score=nan,
estimator=DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None,
criterion='gini', max_depth=None,
max_features=None,
max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
min_samples_leaf=1,
min_samples_split=2,
min_weight_fraction_leaf=0.0,
presort='deprecated',
random_state=42,
splitter='best'),
iid='deprecated', n_jobs=None,
param_grid={'max_leaf_nodes': [2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12,
13, 14, 15, 16, 17, 18, 19, 20, 21,
22, 23, 24, 25, 26, 27, 28, 29, 30,
31, ...],
'min_samples_split': [2, 3, 4]},
pre_dispatch='2*n_jobs', refit=True, return_train_score=False,
scoring=None, verbose=1)
max_leaf_nodes=17, min_samples_split=2일 때, 최적의 하이퍼 파라미터 값이 나옴.
grid_search_cv.best_estimator_
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features=None, max_leaf_nodes=17,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort='deprecated',
random_state=42, splitter='best')
랜덤 포레스트 만들기
- 각각 무작위로 선택된 100개의 n_instances와 1,000개의 n_trees 생성
- 사이킷런의 ShuffleSplit 클래스 활용
from sklearn.model_selection import ShuffleSplit
n_trees = 1000
n_instances = 100
mini_sets = []
rs = ShuffleSplit(n_splits=n_trees, test_size=len(X_train) - n_instances, random_state=42)
for mini_train_index, mini_test_index in rs.split(X_train):
X_mini_train = X_train[mini_train_index]
y_mini_train = y_train[mini_train_index]
mini_sets.append((X_mini_train, y_mini_train))
앞에서 찾은 최적의 하이퍼 파라미터 값을 사용
- clone(grid_search_cv.best_estimator_) 이용
각각의 서브 데이터셋에 결정 트리 훈련, 테스트 세트에서 1,000개의 결정트리 평가
더 작은 데이터셋에서 훈련되었기 때문에 성능이 이전보다 낮다.
from sklearn.metrics import accuracy_score
from sklearn.base import clone
# clone: 동일 파라미터를 가지고 새로운 추정치 생성
forest = [clone(grid_search_cv.best_estimator_) for _ in range(n_trees)]
accuracy_scores = []
for tree, (X_mini_train, y_mini_train) in zip(forest, mini_sets):
tree.fit(X_mini_train, y_mini_train)
y_pred = tree.predict(X_test)
accuracy_scores.append(accuracy_score(y_test, y_pred))
np.mean(accuracy_scores)
0.8054499999999999
각 테스트 세트 샘플에 1,000개의 결정 트리 예측 생성
- SciPy의 mode()를 사용하여 다수결 예측(majority-vote predictions)이 만들어진다.
Y_pred = np.empty([n_trees, len(X_test)], dtype=np.uint8)
for tree_index, tree in enumerate(forest):
Y_pred[tree_index] = tree.predict(X_test)
from scipy.stats import mode
y_pred_majority_votes, n_votes = mode(Y_pred, axis=0)
테스트 세트에서 예측을 평가하면 첫 번째 모형보다 조금 더 높은 정확도를 얻는다.
accuracy_score(y_test, y_pred_majority_votes.reshape([-1]))
0.872np.sum(y_pred == y_pred_majority_votes) / len(y_pred)
0.8995사이킷런 랜덤 포레스트(accuracy_score: 0.8715)
사이킷런을 이용하여 랜덤 포레스트 모델 생성
- n_estimators=1000, max_leaf_nodes=17, random_state=42 설정
from sklearn.ensemble import RandomForestClassifier
rnd_clf = RandomForestClassifier(n_estimators=1000, max_leaf_nodes=17, random_state=42)
rnd_clf.fit(X_train, y_train)
y_pred_rf = rnd_clf.predict(X_test)
사이킷런을 활용한 랜덤 포레스트 예측 값이 위의 직접 랜덤 포레스트 모델을 구현한 예측 값과 비슷하다.
accuracy_score(y_test, y_pred_rf)
0.8715두 모델의 예측 값 비교(98.25% 일치)
직접 구현한 y_pred_majority_votes의 예측 값과 사이킷런의 y_pred_rf 예측 값을 비교한다.
0.9825만큼 일치하는 것을 확인할 수 있다.
np.sum(y_pred_majority_votes == y_pred_rf) / len(y_pred)
0.9825문제 2: 7장 연습문제 9번
스태킹 모델을 직접 구현한 후 7장 강의노트에서 소개한 사이킷런의 스태킹 모델을 사용하는 것과의 성능을 비교하라.
MNIST 데이터셋 가져오기
아래 코드는 MNIST 사진에 포함된 픽셀별 중요도를 이미지로 보여준다.
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784', version=1)
mnist.target = mnist.target.astype(np.uint8)
MNIST 데이터셋을 훈련 세트, 검증 세트, 테스트 세트로 각각 10,000개, 10,000개, 10,000개로 나눈다.
ps. 훈련 세트도 10,000개인 이유는 모델 훈련이 너무 오래 걸려서 입니다. 머쓱2ㅎㅎ;;
from sklearn.model_selection import train_test_split
X_train_val, X_test, y_train_val, y_test = train_test_split(
mnist.data, mnist.target, test_size=10000, random_state=42)
X_train, X_val, y_train, y_val = train_test_split(
X_train_val, y_train_val, test_size=10000, random_state=42)
# 남는 훈련 세트가 50,000개의 이미지 파일
# 스태킹 모델 훈련이 오래 걸리기 때문에 10,000개로 설정
X_train, X_train, y_train, y_train = train_test_split(
X_train, y_train, test_size=10000, random_state=42)
직접구현 스태킹 모델(accuracy_score: 0.9384)
Random Forest, Extra-Trees, SVM, MLP 모델 가져오기
from sklearn.ensemble import RandomForestClassifier, ExtraTreesClassifier
from sklearn.svm import LinearSVC
from sklearn.neural_network import MLPClassifier
# 각각의 모델 적용
random_forest_clf = RandomForestClassifier(n_estimators=20, random_state=42)
extra_trees_clf = ExtraTreesClassifier(n_estimators=20, random_state=42)
svm_clf = LinearSVC(max_iter=20, tol=20, random_state=42)
mlp_clf = MLPClassifier(random_state=42)
estimators = [random_forest_clf, extra_trees_clf, svm_clf, mlp_clf]
for estimator in estimators:
print("Training the", estimator)
estimator.fit(X_train, y_train)
Training the RandomForestClassifier(bootstrap=True, ccp_alpha=0.0, class_weight=None,
criterion='gini', max_depth=None, max_features='auto',
max_leaf_nodes=None, max_samples=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=20,
n_jobs=None, oob_score=False, random_state=42, verbose=0,
warm_start=False)
Training the ExtraTreesClassifier(bootstrap=False, ccp_alpha=0.0, class_weight=None,
criterion='gini', max_depth=None, max_features='auto',
max_leaf_nodes=None, max_samples=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=20, n_jobs=None,
oob_score=False, random_state=42, verbose=0,
warm_start=False)
Training the LinearSVC(C=1.0, class_weight=None, dual=True, fit_intercept=True,
intercept_scaling=1, loss='squared_hinge', max_iter=20,
multi_class='ovr', penalty='l2', random_state=42, tol=20, verbose=0)
Training the MLPClassifier(activation='relu', alpha=0.0001, batch_size='auto', beta_1=0.9,
beta_2=0.999, early_stopping=False, epsilon=1e-08,
hidden_layer_sizes=(100,), learning_rate='constant',
learning_rate_init=0.001, max_fun=15000, max_iter=200,
momentum=0.9, n_iter_no_change=10, nesterovs_momentum=True,
power_t=0.5, random_state=42, shuffle=True, solver='adam',
tol=0.0001, validation_fraction=0.1, verbose=False,
warm_start=False)
개별 실행을 통해 검증 세트 예측과 결과 예측으로 새 훈련 세트 작성
- 각 훈련 샘플은 이미지에 대한 classifiers의 예측 세트를 포함하는 벡터이며 대상은 이미지 클래스이다.
- 새로운 훈련 세트에 대한 classfier 훈련
X_val_predictions = np.empty((len(X_val), len(estimators)), dtype=np.float32)
for index, estimator in enumerate(estimators):
X_val_predictions[:, index] = estimator.predict(X_val)
X_val_predictions
array([[5., 5., 5., 5.],
[8., 8., 8., 8.],
[2., 2., 2., 2.],
...,
[4., 7., 7., 7.],
[6., 6., 6., 6.],
[7., 7., 7., 7.]], dtype=float32)rnd_forest_blender = RandomForestClassifier(n_estimators=200, oob_score=True, random_state=42)
rnd_forest_blender.fit(X_val_predictions, y_val)
RandomForestClassifier(bootstrap=True, ccp_alpha=0.0, class_weight=None,
criterion='gini', max_depth=None, max_features='auto',
max_leaf_nodes=None, max_samples=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=200,
n_jobs=None, oob_score=True, random_state=42, verbose=0,
warm_start=False)rnd_forest_blender.oob_score_
0.942미세 조정을 통해 최적의 블렌더를 선택할 수 있다.
Blender 훈련 후 모든 Classifier에 대해서 스태킹 모델 형성
테스트 세트의 앙상블을 평가해보자.
테스트 세트의 각 이미지에 대해 모든 classifier을 사용하여 예측하고, 다음 예측을 blender에 공급하여 앙상블의 예측 값을 가져온다.
X_test_predictions = np.empty((len(X_test), len(estimators)), dtype=np.float32)
for index, estimator in enumerate(estimators):
X_test_predictions[:, index] = estimator.predict(X_test)
y_pred1 = rnd_forest_blender.predict(X_test_predictions)
from sklearn.metrics import accuracy_score
예측한 값인 accuracy_score의 값이 0.9384가 나온다.
accuracy_score(y_test, y_pred1)
0.9384사이킷런 스태킹 모델(accuracy_score: 0.9491)
사용할 모든 Classifier를 import 한다.
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import LinearSVC
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import make_pipeline
from sklearn.ensemble import StackingClassifier
RandomForest, LinearSVC 모델 적용 StackingClassifier
estimators = [('rf', RandomForestClassifier(n_estimators=20, random_state=42)),
('svr', make_pipeline(StandardScaler(),
LinearSVC(random_state=42)))]
clf = StackingClassifier(estimators=estimators,
final_estimator=LogisticRegression())
clf.fit(X_train, y_train).score(X_test, y_test)
0.9292예측 평가 값이 0.9292으로 직접 구현한 것 보다 점수가 낮다.
하지만 RandomForest, LinearSVC만 적용한 스태킹 모델이기 때문에 이전에 직접 만든 스태킹 모델에서 사용하는 모델들을 가져와서 다시 실행해보자.
RandomForest, ExtraTrees, LinearSVC, MLP 모델 적용 StackingClassifier
estimators = [('rf', RandomForestClassifier(n_estimators=20, random_state=42)),
('ex', ExtraTreesClassifier(n_estimators=20, random_state=42)),
('svm', LinearSVC(max_iter=20, tol=20, random_state=42)),
('mlp', MLPClassifier(random_state=42))]
clf = StackingClassifier(estimators=estimators,
final_estimator=LogisticRegression())
clf.fit(X_train, y_train).score(X_test, y_test)
0.9491예측 평가 값이 0.9491으로 직접 구현한 것 보다 점수가 높다.
훈련 시간이 오래걸려서 훈련 세트를 많이 줄였기 때문에 정확한 훈련이 되지 않았을 수도 있다.
마지막으로 두 모델을 비교하기 위해 y_pred2 값을 따로 저장한다.
y_pred2 = clf.predict(X_test)
두 모델의 예측 값 비교(95.97% 일치)
직접 구현한 y_pred1 예측 값과 사이킷런의 y_pred2 예측 값을 비교한다.
0.9597만큼 일치하는 것을 확인할 수 있다.
np.sum(y_pred1 == y_pred2) / len(y_val)
0.9597
요약
랜덤 포레스트 모델, 스태킹 모델 직접 구현 후 사이킷런의 모델과 성능 비교
랜덤 포레스트 모델
- make_moons 데이터셋을 이용하였다.(참고로 그래프를 확인하면 초승달 모양이 겹쳐져 있는 형식으로 되어있는 데이터셋이다.)
- 사이킷런(sklearn)에서 randomforestclassifier을 이용하여 할 수 있는 내용을 직접 구현하는 내용이다.
- 랜덤포레스트의 n.estimators, max_leaf_nodes 등의 값을 사이킷런의 ShuffleSplit과 accuracy_scores 등을 이용하여 직접 값을 내고 제작하는 형식으로 되어있다.
- 두 모델의 예측 값을 비교하면 98.25%만큼 일치한다.
스태킹 모델
- 스태킹 모델에서는 MNIST 데이터셋을 이용하였다.
- MNIST 데이터셋의 양이 방대하므로 훈련, 검증, 테스트 세트로 3개로 10,000개로 나누었다.
- 스태킹 모델에서 사용할 모델들을 직접 사이킷런으로 실행하여 적용하였다. 사이킷런의 스태킹모델을 사용할 때 모델 또한 일치하도록 하였다.
- 두 모델의 예측 값을 비교하면 95.97%만큼 일치한다.
- 참고 문헌: 핸즈온 머신러닝
- Github link: 머신러닝 실습 6
설명하기 앞서 랜덤 포레스트와 스태킹 모델에 대해서 설명하자면 다음을 이해하면 된다.
랜덤포레스트(Random Forest)란?
우리는 머신러닝으로 데이터 속 특성(Feature)을 수정하거나 결정하는 것을 알 수 있다. 이 특성 정보를 기반으로 데이터를 분리하는 과정을 의사 결정 트리(Decision Tree)라고 한다.
보통 나무(Tree)들이 모여있는 장소를 숲(Forest)이라고 하는데, 랜덤 포레스트(Random Forest)는 이런 의사 결정 트리(Decision Tree)가 모여있는 장소라고 생각하면 된다.
의사 결정 트리에서 한 두가지 요소로 결정하는 것 보다 여러가지 요소를 통해 결정할수록 더 자세한 예측을 할 수 있을 것이다. 그치만 수많은 요소(Feature)들을 가지고 하나의 결정 트리를 만든다고 한다면 가지가 너무 많아 오버피팅의 문제가 생길 수 있다.
즉 랜덤포레스트란 수많은 특성(Feature)들 중에 무작위(Random)로 일부만 선택하여 결정 트리를 생성하고, 이 과정을 여러 번 거쳐 여러 개의 의사 결정 트리를 만드는 방법이다.
여러 결정 트리들의 예측 값 중 가장 많이 나온 값을 최종 예측값으로 정하게 된다.
스태킹(Stacking)란?
스태킹은 여러가지 모델들의 예측값을 최종 모델의 학습 데이터로 사용하는 것이다. 아마 이름도 스택(Stack)이라는 쌓는다는 느낌의 자료구조 형식에서 유래한 것 같다.
간단하게만 설명하자면 이 정도고, 자세한 거는 다른 사람 글 참고하는게 좋을 것 같다.
이제 구현하는 것을 진행해보자.
아 참고로 스태킹 모델 설명보면서 나머지 기본 모델들은 어떻게 구현하냐 생각할 수 있는데,
그거는 그냥 사이킷런으로 들고왔습니다. 머쓱ㅎㅎ;;
기본 설정
- 필수 모듈 불러오기
- 그래프 출력 관련 기본 설정 지정
# 파이썬 ≥3.5 필수 (파이썬 3.7 추천)
import sys
assert sys.version_info >= (3, 5)
# 사이킷런 ≥0.20 필수
import sklearn
assert sklearn.__version__ >= "0.20"
# 공통 모듈 임포트
import numpy as np
import os
# 노트북 실행 결과를 동일하게 유지하기 위해
np.random.seed(42)
# 깔끔한 그래프 출력을 위해
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rc('axes', labelsize=14)
mpl.rc('xtick', labelsize=12)
mpl.rc('ytick', labelsize=12)
# 그림을 저장할 위치
PROJECT_ROOT_DIR = "."
CHAPTER_ID = "decision_trees"
IMAGES_PATH = os.path.join(PROJECT_ROOT_DIR, "images", CHAPTER_ID)
os.makedirs(IMAGES_PATH, exist_ok=True)
def save_fig(fig_id, tight_layout=True, fig_extension="png", resolution=300):
path = os.path.join(IMAGES_PATH, fig_id + "." + fig_extension)
print("Saving figure", fig_id)
if tight_layout:
plt.tight_layout()
plt.savefig(path, format=fig_extension, dpi=resolution)
문제 1: 6장 연습문제 8번
랜덤 포레스트를 직접 구현한 다음에 7장에서 소개한 사이킷런의 랜덤 포레스트 모델을 사용하는 것과의 성능을 비교하라.
직접구현 랜덤 포레스트(accuracy_score: 0.872)
make_moons 데이터셋을 생성
- make_moons(n_samples=10000, noise=0.4) 이용
- 결과를 일정하게 만들기 위해 random_state=42 추가
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=10000, noise=0.4, random_state=42)
make_moons 데이터셋을 train 세트와 test 세트 분할
- train_test_split() 사용
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
DecisionTreeClassifier의 최적 하이퍼 파라미터 찾기: 교차 검증과 그리드 탐색 활용
- GridSearchCV 활용
- max_leaf_nodes 다양한 값 사용
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV
params = {'max_leaf_nodes': list(range(2, 100)), 'min_samples_split': [2, 3, 4]}
grid_search_cv = GridSearchCV(DecisionTreeClassifier(random_state=42), params, verbose=1, cv=3)
grid_search_cv.fit(X_train, y_train)
Fitting 3 folds for each of 294 candidates, totalling 882 fits
GridSearchCV(cv=3, error_score=nan,
estimator=DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None,
criterion='gini', max_depth=None,
max_features=None,
max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
min_samples_leaf=1,
min_samples_split=2,
min_weight_fraction_leaf=0.0,
presort='deprecated',
random_state=42,
splitter='best'),
iid='deprecated', n_jobs=None,
param_grid={'max_leaf_nodes': [2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12,
13, 14, 15, 16, 17, 18, 19, 20, 21,
22, 23, 24, 25, 26, 27, 28, 29, 30,
31, ...],
'min_samples_split': [2, 3, 4]},
pre_dispatch='2*n_jobs', refit=True, return_train_score=False,
scoring=None, verbose=1)
max_leaf_nodes=17, min_samples_split=2일 때, 최적의 하이퍼 파라미터 값이 나옴.
grid_search_cv.best_estimator_
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=None, max_features=None, max_leaf_nodes=17,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort='deprecated',
random_state=42, splitter='best')
랜덤 포레스트 만들기
- 각각 무작위로 선택된 100개의 n_instances와 1,000개의 n_trees 생성
- 사이킷런의 ShuffleSplit 클래스 활용
from sklearn.model_selection import ShuffleSplit
n_trees = 1000
n_instances = 100
mini_sets = []
rs = ShuffleSplit(n_splits=n_trees, test_size=len(X_train) - n_instances, random_state=42)
for mini_train_index, mini_test_index in rs.split(X_train):
X_mini_train = X_train[mini_train_index]
y_mini_train = y_train[mini_train_index]
mini_sets.append((X_mini_train, y_mini_train))
앞에서 찾은 최적의 하이퍼 파라미터 값을 사용
- clone(grid_search_cv.best_estimator_) 이용
각각의 서브 데이터셋에 결정 트리 훈련, 테스트 세트에서 1,000개의 결정트리 평가
더 작은 데이터셋에서 훈련되었기 때문에 성능이 이전보다 낮다.
from sklearn.metrics import accuracy_score
from sklearn.base import clone
# clone: 동일 파라미터를 가지고 새로운 추정치 생성
forest = [clone(grid_search_cv.best_estimator_) for _ in range(n_trees)]
accuracy_scores = []
for tree, (X_mini_train, y_mini_train) in zip(forest, mini_sets):
tree.fit(X_mini_train, y_mini_train)
y_pred = tree.predict(X_test)
accuracy_scores.append(accuracy_score(y_test, y_pred))
np.mean(accuracy_scores)
0.8054499999999999
각 테스트 세트 샘플에 1,000개의 결정 트리 예측 생성
- SciPy의 mode()를 사용하여 다수결 예측(majority-vote predictions)이 만들어진다.
Y_pred = np.empty([n_trees, len(X_test)], dtype=np.uint8)
for tree_index, tree in enumerate(forest):
Y_pred[tree_index] = tree.predict(X_test)
from scipy.stats import mode
y_pred_majority_votes, n_votes = mode(Y_pred, axis=0)
테스트 세트에서 예측을 평가하면 첫 번째 모형보다 조금 더 높은 정확도를 얻는다.
accuracy_score(y_test, y_pred_majority_votes.reshape([-1]))
0.872np.sum(y_pred == y_pred_majority_votes) / len(y_pred)
0.8995사이킷런 랜덤 포레스트(accuracy_score: 0.8715)
사이킷런을 이용하여 랜덤 포레스트 모델 생성
- n_estimators=1000, max_leaf_nodes=17, random_state=42 설정
from sklearn.ensemble import RandomForestClassifier
rnd_clf = RandomForestClassifier(n_estimators=1000, max_leaf_nodes=17, random_state=42)
rnd_clf.fit(X_train, y_train)
y_pred_rf = rnd_clf.predict(X_test)
사이킷런을 활용한 랜덤 포레스트 예측 값이 위의 직접 랜덤 포레스트 모델을 구현한 예측 값과 비슷하다.
accuracy_score(y_test, y_pred_rf)
0.8715두 모델의 예측 값 비교(98.25% 일치)
직접 구현한 y_pred_majority_votes의 예측 값과 사이킷런의 y_pred_rf 예측 값을 비교한다.
0.9825만큼 일치하는 것을 확인할 수 있다.
np.sum(y_pred_majority_votes == y_pred_rf) / len(y_pred)
0.9825문제 2: 7장 연습문제 9번
스태킹 모델을 직접 구현한 후 7장 강의노트에서 소개한 사이킷런의 스태킹 모델을 사용하는 것과의 성능을 비교하라.
MNIST 데이터셋 가져오기
아래 코드는 MNIST 사진에 포함된 픽셀별 중요도를 이미지로 보여준다.
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784', version=1)
mnist.target = mnist.target.astype(np.uint8)
MNIST 데이터셋을 훈련 세트, 검증 세트, 테스트 세트로 각각 10,000개, 10,000개, 10,000개로 나눈다.
ps. 훈련 세트도 10,000개인 이유는 모델 훈련이 너무 오래 걸려서 입니다. 머쓱2ㅎㅎ;;
from sklearn.model_selection import train_test_split
X_train_val, X_test, y_train_val, y_test = train_test_split(
mnist.data, mnist.target, test_size=10000, random_state=42)
X_train, X_val, y_train, y_val = train_test_split(
X_train_val, y_train_val, test_size=10000, random_state=42)
# 남는 훈련 세트가 50,000개의 이미지 파일
# 스태킹 모델 훈련이 오래 걸리기 때문에 10,000개로 설정
X_train, X_train, y_train, y_train = train_test_split(
X_train, y_train, test_size=10000, random_state=42)
직접구현 스태킹 모델(accuracy_score: 0.9384)
Random Forest, Extra-Trees, SVM, MLP 모델 가져오기
from sklearn.ensemble import RandomForestClassifier, ExtraTreesClassifier
from sklearn.svm import LinearSVC
from sklearn.neural_network import MLPClassifier
# 각각의 모델 적용
random_forest_clf = RandomForestClassifier(n_estimators=20, random_state=42)
extra_trees_clf = ExtraTreesClassifier(n_estimators=20, random_state=42)
svm_clf = LinearSVC(max_iter=20, tol=20, random_state=42)
mlp_clf = MLPClassifier(random_state=42)
estimators = [random_forest_clf, extra_trees_clf, svm_clf, mlp_clf]
for estimator in estimators:
print("Training the", estimator)
estimator.fit(X_train, y_train)
Training the RandomForestClassifier(bootstrap=True, ccp_alpha=0.0, class_weight=None,
criterion='gini', max_depth=None, max_features='auto',
max_leaf_nodes=None, max_samples=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=20,
n_jobs=None, oob_score=False, random_state=42, verbose=0,
warm_start=False)
Training the ExtraTreesClassifier(bootstrap=False, ccp_alpha=0.0, class_weight=None,
criterion='gini', max_depth=None, max_features='auto',
max_leaf_nodes=None, max_samples=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=20, n_jobs=None,
oob_score=False, random_state=42, verbose=0,
warm_start=False)
Training the LinearSVC(C=1.0, class_weight=None, dual=True, fit_intercept=True,
intercept_scaling=1, loss='squared_hinge', max_iter=20,
multi_class='ovr', penalty='l2', random_state=42, tol=20, verbose=0)
Training the MLPClassifier(activation='relu', alpha=0.0001, batch_size='auto', beta_1=0.9,
beta_2=0.999, early_stopping=False, epsilon=1e-08,
hidden_layer_sizes=(100,), learning_rate='constant',
learning_rate_init=0.001, max_fun=15000, max_iter=200,
momentum=0.9, n_iter_no_change=10, nesterovs_momentum=True,
power_t=0.5, random_state=42, shuffle=True, solver='adam',
tol=0.0001, validation_fraction=0.1, verbose=False,
warm_start=False)
개별 실행을 통해 검증 세트 예측과 결과 예측으로 새 훈련 세트 작성
- 각 훈련 샘플은 이미지에 대한 classifiers의 예측 세트를 포함하는 벡터이며 대상은 이미지 클래스이다.
- 새로운 훈련 세트에 대한 classfier 훈련
X_val_predictions = np.empty((len(X_val), len(estimators)), dtype=np.float32)
for index, estimator in enumerate(estimators):
X_val_predictions[:, index] = estimator.predict(X_val)
X_val_predictions
array([[5., 5., 5., 5.],
[8., 8., 8., 8.],
[2., 2., 2., 2.],
...,
[4., 7., 7., 7.],
[6., 6., 6., 6.],
[7., 7., 7., 7.]], dtype=float32)rnd_forest_blender = RandomForestClassifier(n_estimators=200, oob_score=True, random_state=42)
rnd_forest_blender.fit(X_val_predictions, y_val)
RandomForestClassifier(bootstrap=True, ccp_alpha=0.0, class_weight=None,
criterion='gini', max_depth=None, max_features='auto',
max_leaf_nodes=None, max_samples=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=200,
n_jobs=None, oob_score=True, random_state=42, verbose=0,
warm_start=False)rnd_forest_blender.oob_score_
0.942미세 조정을 통해 최적의 블렌더를 선택할 수 있다.
Blender 훈련 후 모든 Classifier에 대해서 스태킹 모델 형성
테스트 세트의 앙상블을 평가해보자.
테스트 세트의 각 이미지에 대해 모든 classifier을 사용하여 예측하고, 다음 예측을 blender에 공급하여 앙상블의 예측 값을 가져온다.
X_test_predictions = np.empty((len(X_test), len(estimators)), dtype=np.float32)
for index, estimator in enumerate(estimators):
X_test_predictions[:, index] = estimator.predict(X_test)
y_pred1 = rnd_forest_blender.predict(X_test_predictions)
from sklearn.metrics import accuracy_score
예측한 값인 accuracy_score의 값이 0.9384가 나온다.
accuracy_score(y_test, y_pred1)
0.9384사이킷런 스태킹 모델(accuracy_score: 0.9491)
사용할 모든 Classifier를 import 한다.
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import LinearSVC
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import make_pipeline
from sklearn.ensemble import StackingClassifier
RandomForest, LinearSVC 모델 적용 StackingClassifier
estimators = [('rf', RandomForestClassifier(n_estimators=20, random_state=42)),
('svr', make_pipeline(StandardScaler(),
LinearSVC(random_state=42)))]
clf = StackingClassifier(estimators=estimators,
final_estimator=LogisticRegression())
clf.fit(X_train, y_train).score(X_test, y_test)
0.9292예측 평가 값이 0.9292으로 직접 구현한 것 보다 점수가 낮다.
하지만 RandomForest, LinearSVC만 적용한 스태킹 모델이기 때문에 이전에 직접 만든 스태킹 모델에서 사용하는 모델들을 가져와서 다시 실행해보자.
RandomForest, ExtraTrees, LinearSVC, MLP 모델 적용 StackingClassifier
estimators = [('rf', RandomForestClassifier(n_estimators=20, random_state=42)),
('ex', ExtraTreesClassifier(n_estimators=20, random_state=42)),
('svm', LinearSVC(max_iter=20, tol=20, random_state=42)),
('mlp', MLPClassifier(random_state=42))]
clf = StackingClassifier(estimators=estimators,
final_estimator=LogisticRegression())
clf.fit(X_train, y_train).score(X_test, y_test)
0.9491예측 평가 값이 0.9491으로 직접 구현한 것 보다 점수가 높다.
훈련 시간이 오래걸려서 훈련 세트를 많이 줄였기 때문에 정확한 훈련이 되지 않았을 수도 있다.
마지막으로 두 모델을 비교하기 위해 y_pred2 값을 따로 저장한다.
y_pred2 = clf.predict(X_test)
두 모델의 예측 값 비교(95.97% 일치)
직접 구현한 y_pred1 예측 값과 사이킷런의 y_pred2 예측 값을 비교한다.
0.9597만큼 일치하는 것을 확인할 수 있다.
np.sum(y_pred1 == y_pred2) / len(y_val)
0.9597
요약
랜덤 포레스트 모델, 스태킹 모델 직접 구현 후 사이킷런의 모델과 성능 비교
랜덤 포레스트 모델
- make_moons 데이터셋을 이용하였다.(참고로 그래프를 확인하면 초승달 모양이 겹쳐져 있는 형식으로 되어있는 데이터셋이다.)
- 사이킷런(sklearn)에서 randomforestclassifier을 이용하여 할 수 있는 내용을 직접 구현하는 내용이다.
- 랜덤포레스트의 n.estimators, max_leaf_nodes 등의 값을 사이킷런의 ShuffleSplit과 accuracy_scores 등을 이용하여 직접 값을 내고 제작하는 형식으로 되어있다.
- 두 모델의 예측 값을 비교하면 98.25%만큼 일치한다.
스태킹 모델
- 스태킹 모델에서는 MNIST 데이터셋을 이용하였다.
- MNIST 데이터셋의 양이 방대하므로 훈련, 검증, 테스트 세트로 3개로 10,000개로 나누었다.
- 스태킹 모델에서 사용할 모델들을 직접 사이킷런으로 실행하여 적용하였다. 사이킷런의 스태킹모델을 사용할 때 모델 또한 일치하도록 하였다.
- 두 모델의 예측 값을 비교하면 95.97%만큼 일치한다.
- 참고 문헌: 핸즈온 머신러닝
- Github link: 머신러닝 실습 6